Testing at Scale
Testing at Scale enables AI Managers to understand how configuration changes impact AI Agent behavior. By creating and running test cases, you can verify that updates improve behavior without causing regressions.
Testing at Scale differs from Interactive Testing in that it runs single-turn test cases in bulk, rather than multi-turn conversations one at a time.
Use Testing at Scale for systematic validation at scale—including regression testing, compliance audits, and deployment readiness.
Use Interactive Testing for quick checks and qualitative exploration.
Overview
When you modify an AI Agent—whether by updating Knowledge, adjusting Actions, or refining Playbooks, predicting the full impact across all support scenarios is difficult. Testing at Scale addresses this challenge by allowing you to define a set of test cases, simulate end-user inquiries, and evaluate the AI Agent’s simulated responses against the expected outcomes you define.
With Testing at Scale, you can:
- Create a library of test cases that you can run anytime to understand how your AI Agent is behaving
- Quickly test across end-user segments to ensure coverage of real-world situations
You can run up to 300 tests per day. Test conversations are subject to your plan terms. If you need additional capacity, contact your Ada representative.
Limitations
Testing at Scale has the following constraints:
- Single-turn conversations only: Each test simulates a single exchange between an end user and the AI Agent. Multi-turn conversations are not currently supported.
- Web Chat, Email, and Voice channels only.
- Manual test case creation: Test cases must be created individually through the dashboard; bulk import isn’t supported. Test cases can be created in bulk with the help of your Ada CX partner.
- Voice simulation audio playback: Audio playback latency between the simulated end user and AI Agent’s response is not representative of production conversation latency.
- Pass/fail evaluations only: Expected outcomes produce binary pass/fail results. Complex scoring or weighted evaluations are not available.
- Production configuration only: Tests run against the current published AI Agent configuration. Draft or staged changes cannot be tested in isolation. However, you can use availability rules to publish changes that are not yet live with end users, then run tests against that configuration.
- No direct dashboard export: Test results cannot be exported directly from the dashboard. Test cases and results can be exported as CSV through the MCP Server.
- Default settings: Language defaults to English and channel defaults to Web Chat unless specified during test case creation.
Both simulated responses and evaluations are powered by generative AI. Some minor variability in responses and evaluation results is expected between test runs. To improve consistency, use clear and specific expected outcomes, ensure relevant Coaching and Custom Instructions are in place, and re-run tests periodically to observe trends over time.
Tests run separately from live traffic and do not affect production performance. You can run tests at any time without impacting end-user conversations.
Single-turn behavior by capability
A single turn includes one end-user message followed by one AI Agent reply. The turn ends when the Agent provides a relevant answer, requests more input, or reaches a handoff point.
Simulated responses use the same capabilities available to the AI Agent in real conversations, with one constraint: Testing at Scale currently supports only single-turn responses. This affects different capabilities as follows:
Use cases
Testing at Scale supports several common workflows:
- Pre-deployment validation: During initial AI Agent configuration, validate behavior across key scenarios before launching to end users.
- Regression Testing: After updating Knowledge articles or modifying Actions, re-run existing test cases to confirm the changes produce expected results without causing regressions.
- Continuous improvement: Post-deployment, run tests regularly to monitor AI Agent performance and identify areas for improvement.
- Major update validation: Before and after significant changes, run comprehensive test suites to catch unintended downstream impacts.
- Coverage validation: Create test cases representing different end-user segments, languages, and channels to ensure the AI Agent handles a broad range of real-world situations.
- Deployment readiness: Run a full test suite before deploying changes, generating clear pass/fail metrics to share with stakeholders and support go/no-go decisions.
- Compliance and safety audits: Validate AI Agent behavior for compliance-sensitive scenarios and edge cases.
Capabilities & configuration
Testing at Scale provides automated conversation testing capabilities through structured test cases.
Test case structure
Each test case includes the following elements:
Test case examples
The following examples illustrate how to structure test cases for common scenarios:
Test results
Each test run generates pass/fail results for individual expected outcomes and an overall status for the test case. Results also include a rationale explaining each judgment and a list of generative entities (Knowledge, Actions, Playbooks, etc.) used to produce the response. For more details, see Review results.
Quick start
Get started with Testing at Scale in just a few steps. For detailed instructions, see Implementation & usage.
Create a test case
In your Ada dashboard, navigate to Testing, and click Add. Enter a Test case name, a Customer inquiry, select the Language and Channel (Web Chat, Email, or Voice), and define at least one Expected outcome. Then, click Save.
Run the test
Select your test case and click Test. The AI Agent simulates a response and evaluates it against your expected outcome.
Implementation & usage
Create test cases, run tests, and review results to validate your AI Agent’s responses.
Create a test case
Test cases define the end-user inquiry and expected outcome that the AI Agent’s response is evaluated against. Each test case captures a specific scenario you want to validate, making it reusable for regression testing and ongoing verification.
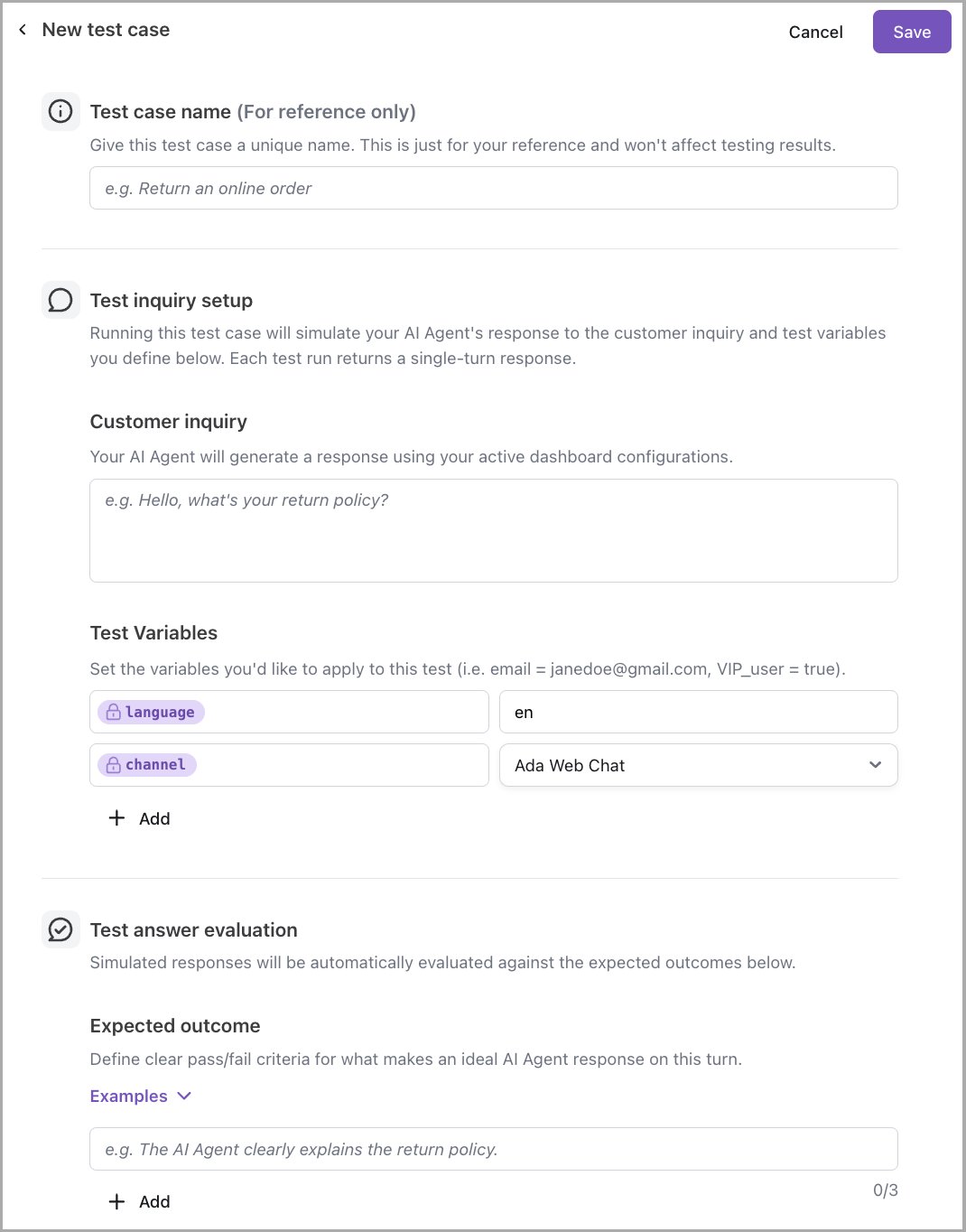
Test case name
The Test case name should be descriptive and clearly reflect the scenario being tested—for example, Refund policy accuracy or Password reset initiation. A clear name makes it easier to identify test cases when running batches or reviewing results.

Test inquiry setup
Test inquiry setup defines what the AI Agent receives and the context in which it responds.
-
Customer inquiry: The message the AI Agent receives, simulating what an end user would send. This should reflect realistic phrasing and context.
-
Test Variables: Variables allow test cases to simulate specific end-user contexts, such as language preferences or channel type. Adjusting values like
languageandchannelhelps ensure the AI Agent’s response reflects real-world conditions.
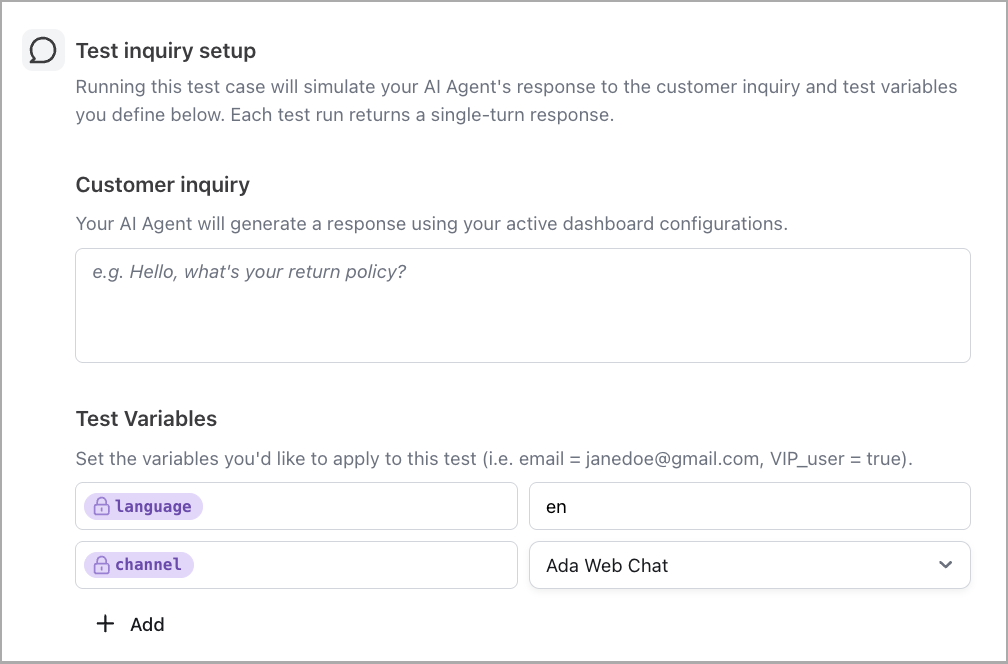
Test answer evaluation
Test answer evaluation defines what the AI Agent’s response must achieve to pass. The AI Agent’s response is evaluated against each criterion independently, producing:
-
A pass/fail result per criterion
-
An overall pass/fail for the test case
-
A rationale explaining each judgment
-
Expected outcomes: Each test case requires at least one expected outcome and supports up to three. Write outcomes that are specific and measurable—for example, instead of
responds helpfully, useprovides the return policy timeframeorincludes a link to a help article. Clear, well-defined outcomes produce more reliable pass/fail evaluations and meaningful rationale.
Add a new test case
You can add test cases from the Testing page in your Ada dashboard.
To create a test case:
- In your Ada dashboard, navigate to Testing, then click Add.
- On the Testing page, enter a Test case name.
- Under Test inquiry setup, enter a Customer inquiry and optionally add Test Variables to simulate specific end-user contexts.
- Under Test answer evaluation, add at least one Expected outcome.
- Click Save to create the test case.
Edit or delete a test case
You can modify or remove existing test cases from the Testing page.
To edit a test case:
- In your Ada dashboard, navigate to Testing.
- Select the test case you want to edit from the list on the left.
- In the test case section on the right, click the three dots in the top-right corner and select Edit.
- Update the Test case name, Test inquiry setup, or Test answer evaluation as needed.
- Click Save to apply your changes.
To delete a test case:
- In your Ada dashboard, navigate to Testing.
- Select the test case you want to delete from the list on the left.
- In the test case section on the right, click the three dots in the top-right corner and select Delete.
Run tests
Test runs execute one or more test cases against the current published AI Agent configuration. Each test simulates a single-turn conversation where the AI Agent generates a response and evaluates it against the defined expected outcomes.
Select and run test cases
Tests can be run individually to validate specific scenarios, or in batches to evaluate broader coverage. Batch testing is useful for regression testing after configuration changes or for validating deployment readiness across multiple scenarios at once.
-
Selecting multiple test cases and running them together produces a consolidated test run with results for each case.
-
Test runs execute separately from live traffic and do not affect production performance.
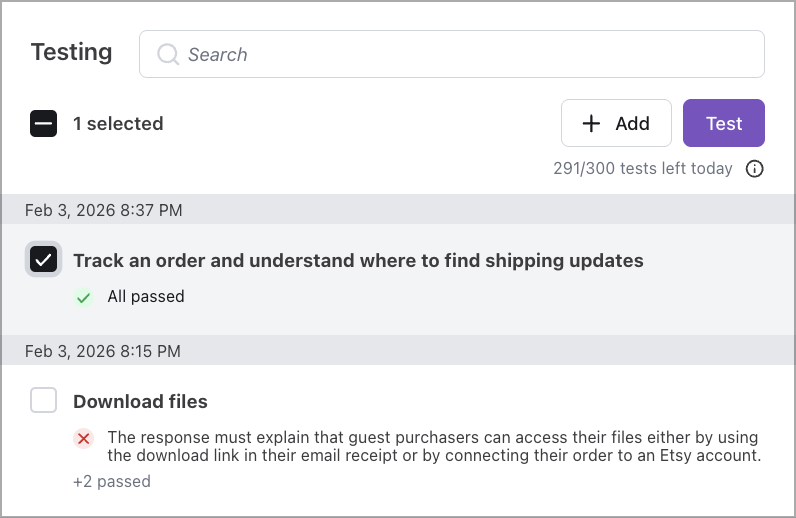
To run tests:
- In your Ada dashboard, navigate to Testing.
- On the Testing page, select one or more test cases on the left.
- Click Test and wait for the test run to complete.
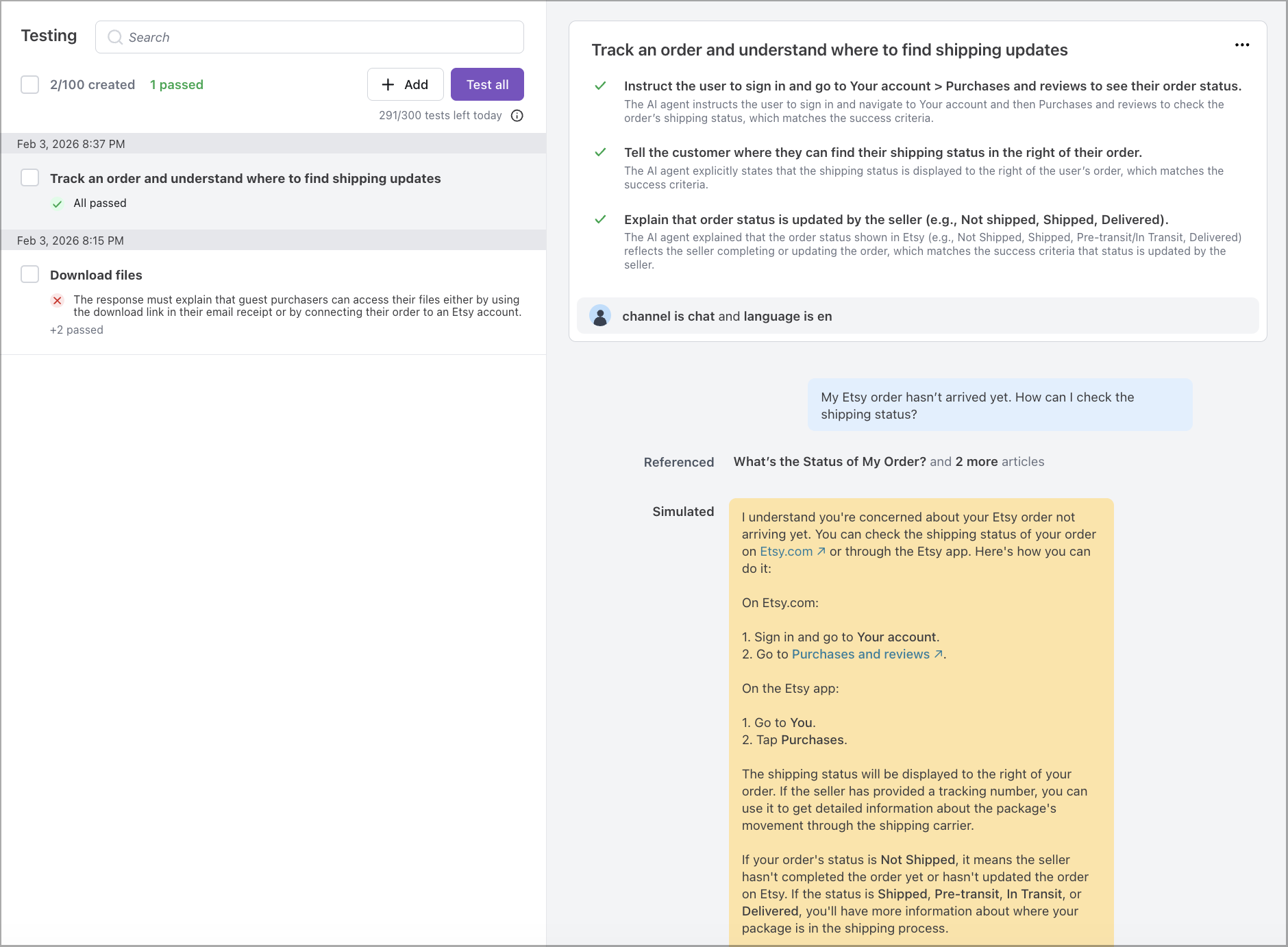
Review results
Test results provide visibility into how the AI Agent performed against each expected outcome. Results include pass/fail status, evaluation rationale, and details about which tools were referenced by the AI Agent to generate its response.
Each test case displays an overall pass/fail status based on whether the AI Agent’s response met all defined expected outcomes. Individual criterion results are also available, allowing you to identify which specific expectations passed or failed.
Clicking into a test case reveals additional context:
-
AI Agent response: The full response generated during the test.
-
Audio playback (Voice channel only): A simulated audio recording of the AI Agent’s and simulated end user’s message. The AI agent’s response is generated using the configured speaking voice for the selected language, while the simulated end user message uses one of four default voices.
-
Evaluation rationale: An explanation for each criterion judgment, describing why the response passed or failed.
-
Generative entities used: A list of Knowledge, Actions, Playbooks, and other configuration elements that contributed to the response.
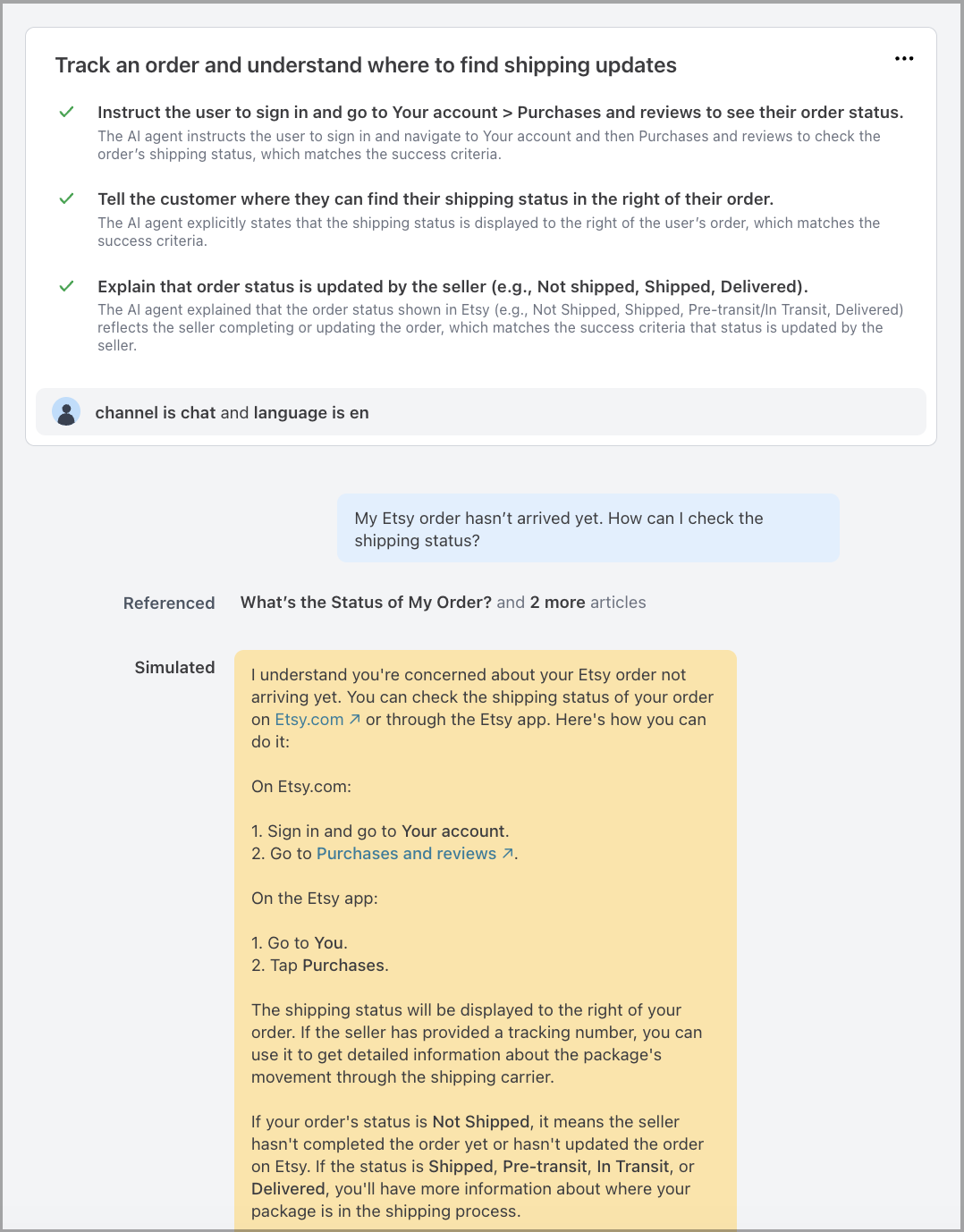
To review test results:
- In your Ada dashboard, navigate to Testing.
- Select a completed test run to view the results.
- Select a test case to see the response details, evaluation results, and rationale.
Improvement actions
Failed test cases highlight areas where the AI Agent’s behavior does not meet expectations. The results provide the context needed to diagnose issues and make targeted improvements.
Evaluation rationale
Each test result includes an evaluation rationale that explains why each criterion passed or failed. The rationale provides insight into the AI Agent’s reasoning and helps identify whether the issue stems from missing Knowledge, incorrect Action behavior, Playbook logic, or other configuration.
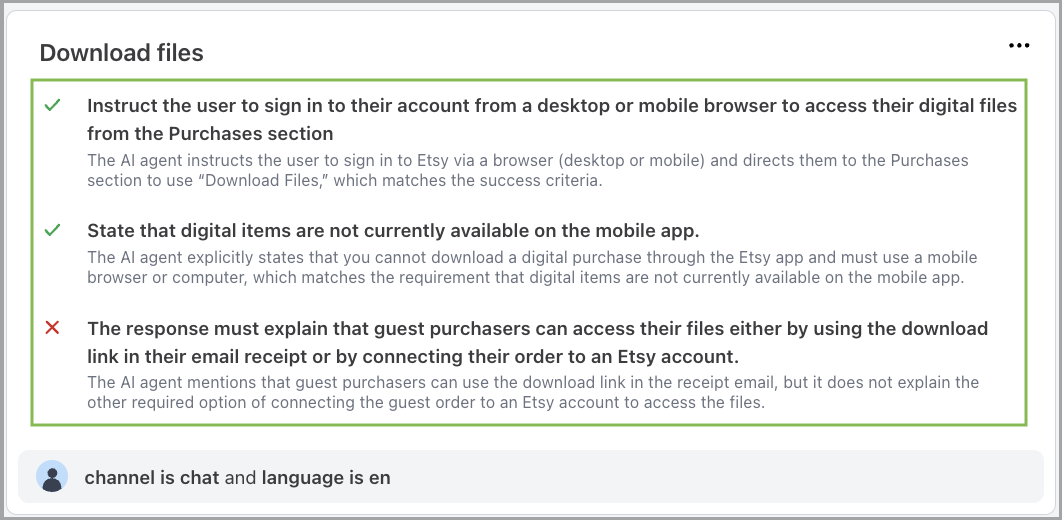
Configuration links
Test results include direct links to the generative entities—such as Knowledge articles, Actions, or Playbooks—that contributed to the response. These links provide quick access to the relevant configuration, making it easier to locate and update the source of an issue.

Iterative improvement
Re-running test cases after making changes confirms whether updates resolved the issue. This cycle of testing, diagnosing, and improving supports continuous refinement of AI Agent behavior over time.
Related features
These features complement Testing at Scale and support AI Agent optimization:
-
Interactive Testing: Test your AI Agent in real time by chatting with it directly, simulating different user types with variables.
-
MCP Server: Retrieve test cases, test run results, and quota information, or export test data as CSV through a connected AI assistant.