Personalization data
Personalization in Ada relies on using what you know about your users—like their name, region, or support plan—to deliver relevant and tailored interactions. It focuses on using data-driven insights to personalize each user’s experience.
For example, your AI Agent can greet users by name and offer “Gold” members exclusive offers or priority support, thanks to profile data like membership level or support plan. If missing, Ada can capture details like order number mid-conversation and update the profile immediately—ensuring precise, personalized replies for every interaction.
This page shows how that information moves between Ada and your systems, how the Personalization Engine consumes it, and how the available logic layers turn it into a custom conversation.
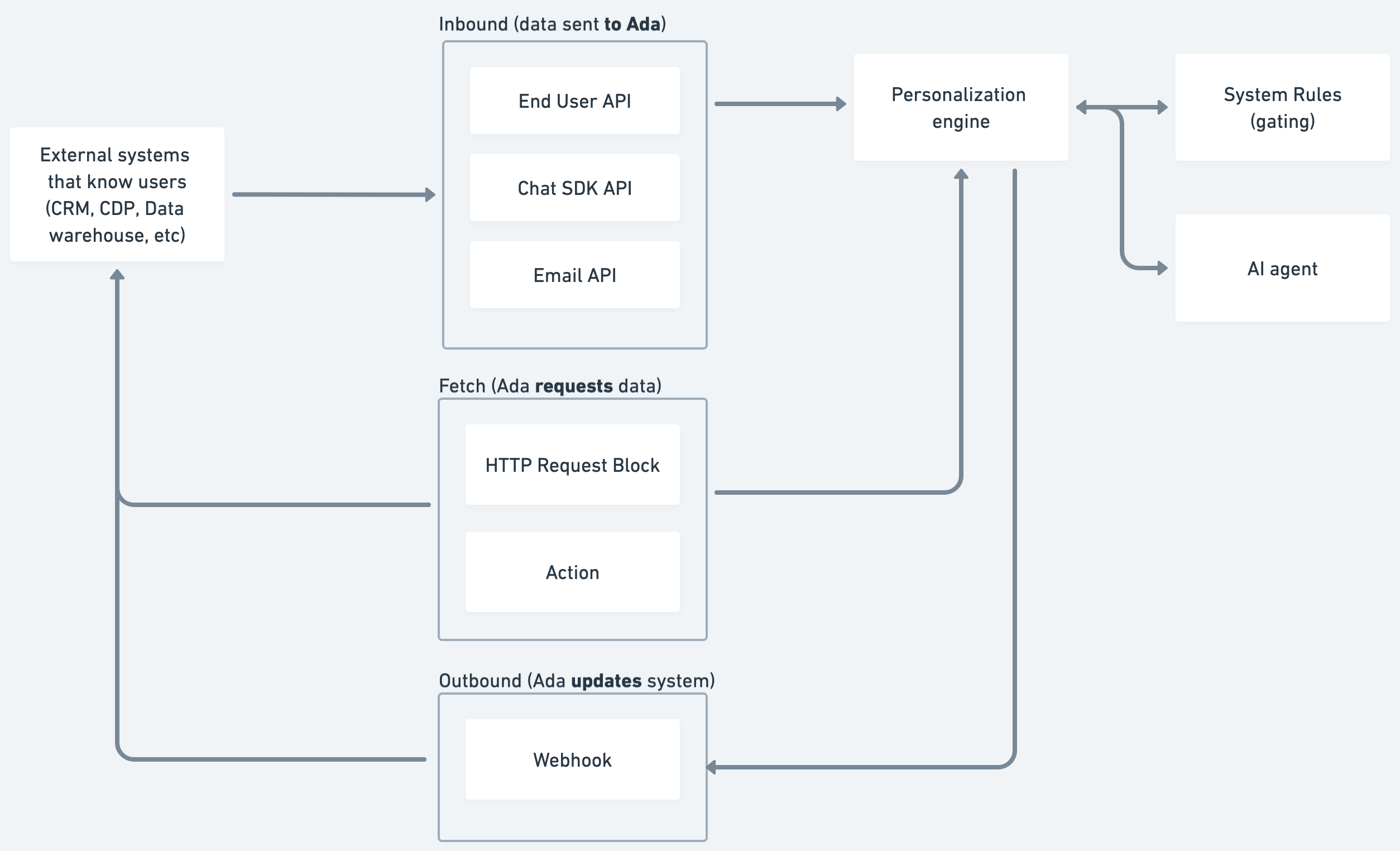
How the Personalization Engine uses profile data
System Rules (gating)
Deterministic rules decide which Knowledge, Coaching, Actions, Processes, and Handoffs are available.
Example: Show onboarding articles only to Enterprise plans or offer a priority hand-off to users in Europe.
AI Agent (tailored reply)
All variables—plus any new data gathered during the session—are provided as context to the model so each reply reflects the user’s situation.
Example: Greet by name, adjust instructions after fetching live account data.
Integration paths
Inbound paths: Preloaded personalization data
This category focuses on data pushed into Ada at the start of the conversation.
End Users API
If your backend system already stores information about your users—such as names, locations, or subscription tiers—you can use the End Users API to sync that data into Ada.
For example, imagine a user logs into your app and begins a conversation with your AI Agent. Ada automatically creates a user profile at that moment and fires a webhook event notifying your system of the new profile. Your system can then send a PATCH request to the End Users API, updating the user’s profile with metadata.
For example:
These values are saved as variables in the user’s profile and are immediately available to the system to determine content availability through rules in Knowledge, Coaching, Actions, Processes, and Handoffs and to AI Agent to access, respond to, and adapt the conversation accordingly.
This approach is ideal when you already have a reliable user identifier (like an email or internal ID) and want to enrich the profile. It also works across all supported channels.
Chat SDKs
For web or app-based chat experiences, personalization can be handled directly using the Chat SDKs.
Let’s say a user logs into your website and opens the Ada Chat. If their name, email, or customer ID is already available in your app, you can pass that data into the chat when it loads using metaFields. Alternatively, if the user logs in after the chat has already loaded, you can update their profile using setMetaFields. In both cases, this data is stored in the user’s profile as variables.
These values become available immediately and can be used to personalize replies (e.g., “Hi [name]”) or to determine content availability through rules in Knowledge, Coaching, Actions, Processes, and Handoffs. This method is limited to chat, but works well when user-specific data is available from the hosting site or app.
Email Conversations API
Ada can receive personalization data as part of an inbound email conversation using the Email Conversations API.
Imagine a support request comes through a contact form. Your system forwards the request to Ada via a POST call to the Email Conversations API, including the user’s name, email address, and any relevant metadata—such as ticket_id or product_tier. When this call is received, Ada automatically creates a user profile, and the metadata is stored as variables.
Because this data is attached to the user profile up front, it can be used immediately in the conversation and for content gating, even before the AI agent sends a reply. Variables in the user’s profile are available right away for personalization or to determine content availability through rules in Knowledge, Coaching, Actions, Processes, and Handoffs. This method is specific to the Email channel but is highly effective when profile data is already known at the start.
Data fetching: Getting fresh information during conversations
This category focuses on dynamic, on-demand information that’s collected and used mid-conversation to personalize the AI Agent’s replies. Unlike the Inbound flow, which relies on data known upfront, Fetch allows the AI Agent to reach out to your system, like an order tracking API or account management system, to bring back the latest updates.
HTTP Request block
Ada also allows you to update a user’s persistent profile (profile.metadata) directly from the conversation. To do this, you can configure a Request block to send a PATCH request to the End Users API. The Request block must target the specific user’s endpoint URL (https://{bothandle}.ada.support/api/v2/end_users/{end_user_id}), with the end_user_id dynamically inserted. An Authorization header is required, passing the API key as a Token. In the body of the request, the payload must be structured under a profile object, containing the key-value pairs you want to update.
For example, if the user’s name and plan are captured during the conversation, the Request block could send the following:
Request blocks are available as part of Greetings, Processes and Handoffs. This approach allows you to immediately enrich the user’s profile with newly collected information, making it available for future personalization and access control.
Actions and Processes
Actions let the AI Agent make API calls during a conversation to retrieve real-time data—like order status or account details—so it can tailor replies dynamically. Actions can prompt users for inputs (e.g., an email or order ID) and map parts of the API response to outputs that the AI Agent uses in its responses. You configure them in the Ada dashboard by setting up the API call, authentication, and specifying which parts of the response to include in replies.
When Actions are part of Processes, they become steps in a carefully orchestrated, multi-step flow. These Processes let you chain together data-fetching Actions, creating rich, dynamic personalization that complements the profile data already available at the start of the conversation.
Outbound: Updates to your system
Outbound integration paths ensure your system stays informed about key events in conversations.
Webhooks are real-time notifications that Ada sends to your system whenever something important happens—like when a new end user is created or an existing profile is updated. For example, in the End Users API, there’s a webhook sent when an end user is created and another one when an end user is updated—ensuring your systems stay in sync with Ada’s data.
Privacy and retention
Personal data—such as a customer’s full name, email address, phone number, unique identifiers, and other details defined under privacy laws—is carefully protected. Redaction can be applied based on customer settings. Robust safeguards, including a Zero Data Retention policy for LLM providers, prevent unintended data storage. For more details, customers can consult the Trust Center, Privacy Team, DPO, or their account manager